What Is the Submitty Autograder?
The Submitty Autograder is the component of Submitty responsible for compiling and executing student code and comparing its output to an instructor’s solutions. The autograder has three components to it:
- Autograding workers. These are where student code is ultimately run and their output graded. There may be multiple of these in a Submitty system, and they may either be processes running on a Submitty primary machine (the server which hosts the Submitty website), or they may be one or more processes running on some remote machine.
- The autograding scheduler. Since we only have a finite number of autograding workers, we can only grade so many student submissions at one time. The scheduler determines which student assignments are graded first, as well as which workers get to grade said assignments.
- Autograding shippers. There is one of these for every Submitty autograding worker. They receive jobs from the scheduler and are in charge of sending these jobs to their paired shipper. Once the job has been received by the worker, the shipper periodically polls the job to see if it has finished grading or not and, once it has finished, pulls the results back to the primary machine and writes the grade data into the proper places.
The Life of a Submission
A submission begins its life when a student clicks the “Submit” button on a gradeable. From there, the submission’s files are uploaded onto the primary machine, and a queue file is placed in the autograding queue folder. This queue file identifies which submission should be graded as well as when it was placed in the queue.
The scheduler periodically polls the queue folder for new jobs. When the scheduler finds jobs in the queue folder, it takes the oldest jobs and moves them into the shipper directories of workers which are currently idle (not grading any submissions). Once there, each queue file waits to be sent to the worker by the shipper.
Just like the scheduler, the shipper periodically scans its own directory for jobs. When it detects a job placed in its directory, it opens the queue file, packages the corresponding submission files into a zip file, and sends the zip file to a place where the worker can see it. In the case that the worker is a local worker, then it moves the zip file to the directory the worker monitors. In the case that the worker is a remote worker, then the zip file is sent over SCP to the remote worker.
Once the worker picks up the queue file, it goes through the entire grading process. This process can vary significantly depending on the gradeable’s configuration. Once grading finishes, the worker creates a results zip file containing the results of the autograding. On the shipper side, the shipper queries the worker’s directory (either via local file management operations or via SSH) periodically for the results zip file. Once the results zip file is generated, the shipper pulls the results zip from the worker and extracts it into the primary machine’s results folder, at which point the student is able to see their submission’s results. Then, the cycle begins once again.
Motivation and Goals
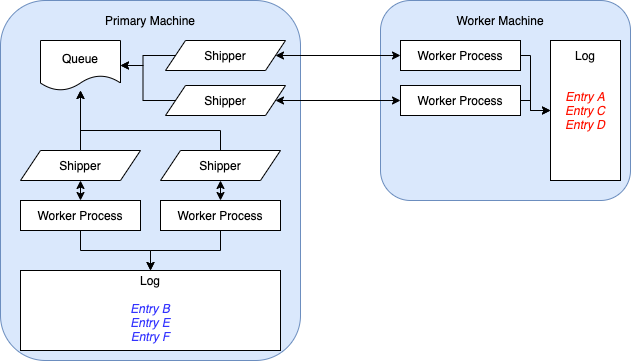
The diagram above is a snapshot of the state of the Submitty Autograder when I joined Submitty back in Fall 2019. Two things stand out about this design:
- There is no real scheduler. Instead, the shipper processes all fight each other for jobs in the queue folder. This limits our ability to potentially schedule autograding jobs in a more intelligent manner, as well as being overall kind of a messy thing to deal with.
- Autograding log entries are scattered everywhere throughout the system. This is significant because it means that a system administrator would have to inspect the primary machine’s logs to figure out on which machine the issue occurred, so that they may then log on to the failing machine (or machines, if the error occurs on multiple machines) and inspect the logs there. It would be nicer to have copies of worker error logs available on the primary machine.
Not visible in the diagram is the maintainability of the system. The autograder had grown organically over several years and, as a result, suffered from some maintainability issues, particularly on the shipper end. Functions were very long and their functionality was difficult to grok. Making changes to the code was a very fear-wrought process, as the autograder code lacked unit tests, so any small change could introduce a very subtle bug that wouldn’t be caught by the site integration tests. Thus, my Master’s Project aimed at tackling this issue. My contributions to Submitty can be summarized like so:
Scheduling
Centralized Scheduling
Originally, there was no true autograding scheduler – any “scheduling” that happened was a byproduct of the shippers’ original algorithm, summarized below:
- Lock the autograding queue directory.
- Get a list of files in the queue directory that do not represent submissions currently being graded.
- Pick the oldest one, mark it as being graded, and send it to the worker.
- Unlock the autograding queue directory.
- Wait for the current submission to finish grading.
- Retrieve the current submission’s results and save them.
- Return to Step 1.
Although this works, this has the potential issue of bottlenecking very easily since at any given moment only one shipper can check for new jobs. This is particularly noticeable on a system where the Submitty primary machine has slow I/O. Furthermore, the decentralized nature of the scheduling behavior limits what kinds of smart scheduling are possible.
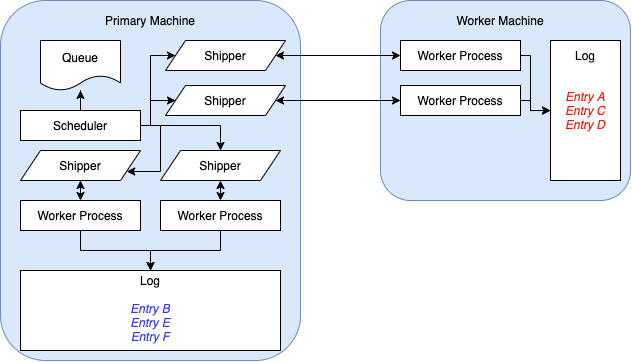
PR #4745 modifies this behavior so that scheduling decisions happen on the same thread that monitors the shippers. Each shipper now queries its own private directory, so filesystem locking is no longer necessary. Furthermore, scheduling happening on a centralized process adjacent to the shippers means that it is easier to modify the scheduling behavior. The image below showcases the autograder’s structure after the changes made by this PR. Note the new “scheduler” node and how it pushes jobs to each shipper node.
Short-Circuiting Non-Autograding Submissions
PR #5527 allows for submissions we deem as “trivially gradeable” to skip most of the autograding process. We currently define a trivially gradeable submission as one that only has a lateness check associated with it. When a shipper picks up a job that is trivially gradeable, it performs the lateness check itself, docks points if necessary, and records the submission’s results. Because this skips the worker portion of the autograding process, such submissions are now graded much more quickly than before.
Logging
Logging Centralization
The Submitty autograder writes two different types of logs: regular logs, and stack trace logs. Regular logs simply provide transparency into how the autograder is currently running, whereas stack trace logs report major errors that occur. The Submitty primary machine and each of the worker machines keep their own independent copies of both logs. This means that inspecting the logs when autograding failures occur can become a bit of a hassle, as it may be necessary to log into one or more worker machines to find out what went wrong.
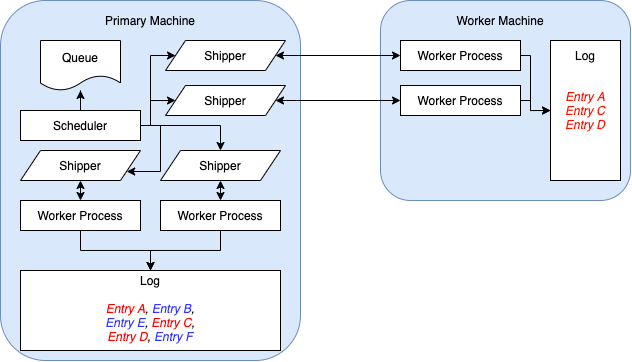
PR #6062 revamps the autograding logger interface so that stack trace logs are replicated in a central location (the Submitty primary machine) when possible. The worker keeps track of all calls to the “log stack trace” function, and stores this record in its results file. When the corresponding shipper receives the results file and discovers that the “log stack trace” function was called on the worker’s end, it reproduces those entries in the primary machine’s stack trace log. The image below showcases the state of the autograder after pushing this change. Note how the primary machine now also includes logs from the worker machine, respecting the order with respect to the worker machine.
Student Logs (W.I.P.)
Currently, if a submission suffers from some kind of autograding-related error, the student receives a message stating “Something went wrong with this submission.” This is admittedly not a very helpful error message, and figuring out the source of the error usually involves an administrator looking through the autograding logs to figure this information out. The goal of the tentatively-named “Student Logs” feature is to provide extra feedback to the user on autograding failure so that narrowing down the source of the issue is a more streamlined process. For instance, if autograding fails due to a Docker misconfiguration in the gradeable, this information can be propagated to the instructor much more quickly.
Student Features
Autosaving in Notebook Gradeables
PR #5323 introduces autosaving to notebook gradeables. This is part of an ongoing initiative to help reduce the load on the autograder when notebook gradeables are used for distributing exams. Students may submit multiple times to these gradeables as a method of saving their progress. Notebook autosaving is local-only, but it helps safeguard a student’s exam progress from potential catastrophe (e.g. a browser crash) without having to use up the worker’s available compute for results that are ultimately going to be discarded anyway.
Grading Worker Display
PR #6175 introduces a new
“graded by worker” field to the autograding results page. Although minor, this
tweak can significantly help gradeable debugging time when dealing with
heterogeneous sets of workers. For example, consider a setup with two workers
A and B set up to grade graphics assignments. A and B have different
graphics cards, and as a result might have slight inconsistencies in how they
render graphics. Because of these inconsistencies, one student might lose
points when grading on worker B, but not when grading on worker A.
Displaying which worker machine graded a submission helps with debugging these
instances, as it is no longer necessary to dig deep into the autograder logs
to figure out which worker graded a certain submission – this information can
be provided directly by the student.
Refactors and Testing
File Copy Refactor
PR #5867 introduces a suite of generic “copy/delete” functions to the autograding shipper that decide based on the destination hostname whether the file access should be done via the operating system’s regular local file management functions (for managing files on workers running on the primary machine) or via SSH (for managing files on remote workers). This helps make the surrounding code easier to understand, as the functions where these file management operations occur are shorter as a result and easier to understand. The table below shows the line counts of the refactored functions before and after the refactor.
| Function | Line Count (Before) | Line Count (After) |
|---|---|---|
update_worker_json |
105 | 54 |
prepare_job |
119 | 92 |
unpack_job |
224 | 186 |
Vagrant Sample Courses Capabilities
Each gradeable that can be autograded is assigned a capability by the instructor. This tells the autograding scheduler which workers are allowed to grade this and allows for a Submitty setup to have workers dedicated to specific tasks. For example, there could be one worker machine dedicated to running Python assignments, one worker machine dedicated to running C++ assignments, etc.
PR #6264 modifies the setup scripts for the development VM environment so that the sample courses have multiple capabilities associated with them. This lays the groundwork for more sophisticated testing of the autograding infrastructure.
Autograding Scheduler Unit Tests
PR #6191 introduces unit tests for the autograding scheduler, while also refactoring the scheduler’s behavior into its own separate class following a specific interface. Unit tests for the scheduler help improve our testing coverage of the Submitty autograding infrastructure, whereas refactoring the scheduler into its own separate class lays the groundwork for more configurable autograding scheduler behavior. For example, one administrator may want to preserve First-Come-First-Serve scheduling, whereas another administrator in a different institute might prefer some other scheduling algorithm.
Future Work
Scheduling and the Thursday Problem
The current scheduling algorithm used in Submitty is a very simple first-come-first-serve algorithm. While it is “fair” in a sense, issues arise when it comes to mixing and matching different classes. This manifests in something I like to call “The Thursday Problem:” at RPI, one of the introductory Computer Science courses, Data Structures, schedules homeworks weekly to be turned in by the end of day on Thursday. As it is an introductory course, there are hundreds of students enrolled in it at the same time. This means that every Thursday, Submitty gets flooded with hundreds of Data Structures submissions as the midnight deadline approaches.
At the beginning of the semester, this can pose a minor annoyance to students taking higher level courses, such as Operating Systems. In these higher-level courses, homework code tends to be more complex and as a result takes longer to grade, although there tends to be far fewer students in these courses and homeworks are far more spread out. This means that students of these courses who find themselves in the unfortunate position of submitting on a Thursday night will get caught in the flood of Data Structures submissions and may find themselves waiting several minutes until their submission begins grading. This becomes more and more of an issue as the semester goes on – Data Structures assignments become more complex and therefore require more time to grade, which means our hypothetical Operating Systems student could be waiting for over half an hour for feedback if they’re unlucky.
Because of this, it would be interesting to experiment with various different scheduling algorithms in order to make a system that’s perhaps more “fair” in a different sense of the word. Furthermore, a more sophisticated algorithm could help overcome some trickier constraints. For example, a worker might have the computational capacity to grade multiple small assignments or one big assignment. How “heavy” an assignment is is not something that the scheduler currently takes into account.