Instructors access Lichen by clicking on the “Plagiarism Detection” link from the left sidebar. Instructors can create new plagiarism detection configurations for gradeables and edit or re-run existing configurations. The Lichen tool enables you to create multiple configurations per gradeable, where each configuration gets a unique ID, which allows running the tool on the same set of submissions under different settings.
Plagiarism Main Page
The plagiarism main page displays a summary table of the results from previous runs of existing gradeable configurations, as well as those that are currently running. Each row in the table represents a gradeable configuration, and contains the information on the gradeable name, configuration ID, run timestamp, number of students submitted and total number of submissions, and an overview of the run results.
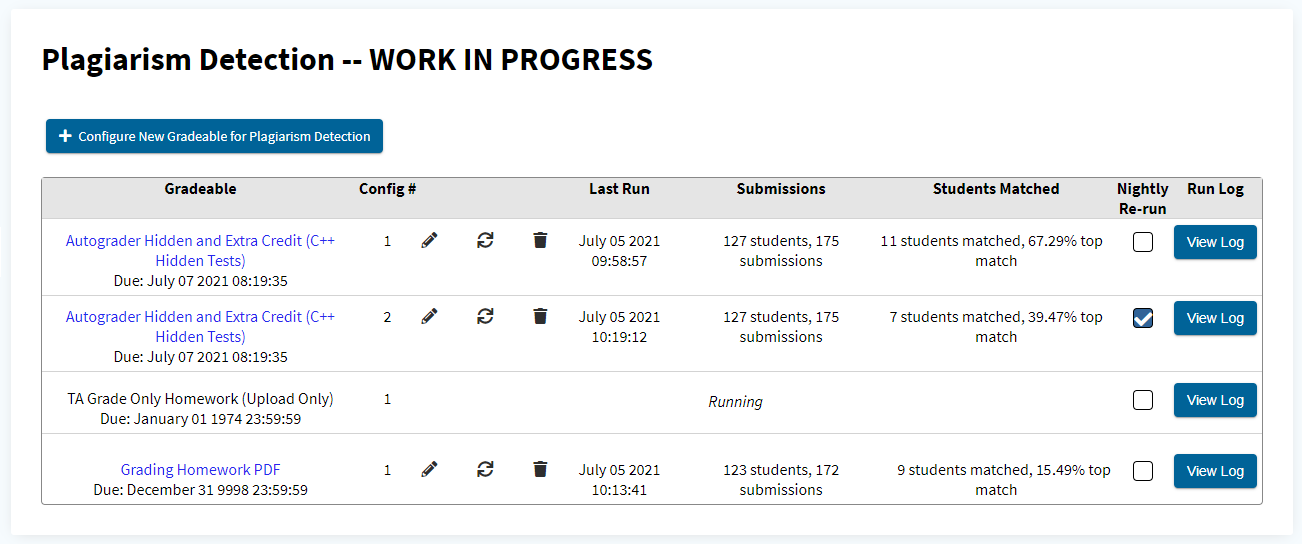
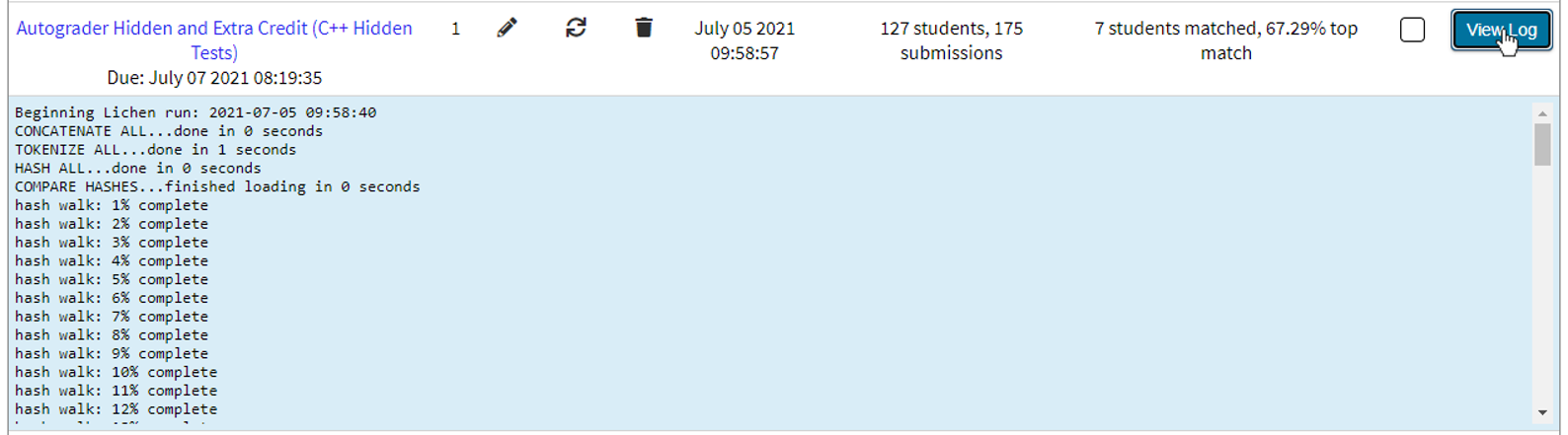
The log of a run for a configuration can be viewed at any time by clicking the “View Log” button, which will toggle a preview of the output of the Lichen processes which are taking place as part of the plagiarism detection algorithm. This can be useful for tracking the progress of lengthy runs, or for troubleshooting in case a configuration does not run as expected.
TODO: nightly rerun feature
Creating a New Configuration
To create a new configuration for a gradeable, from the main plagiarism page, click the “Configure New Gradeable for Plagiarism Detection” button, which will open a form with the different customizable parameters for the configurations, described below.
Gradeable
The configuration form allows you to select a gradeable from a dropdown of all the gradeables in the course that have submissions, on which you want to run the plagiarism detection. If you select a gradeable that already has an existing configuration, then submitting the new configuration form will create another one, with a new unique ID. Different configurations for gradeables are independent from each other, so editing, re-running, or deleting one configuration for a gradeable will not affect the other existing ones.
Instructor Provided Code
The “Instructor Provided Code” file upload is an optional field in the form. The uploaded files will be used in the matching algorithm to identify regions in student submissions that match the provided code for that assignment. Those matching regions will not be considered plagiarized regions, and will be specifically marked as “provided code” in the run results UI.
Version
Instructors can configure to either include all versions of students’ submissions, or just the active version of students’ submissions to be included and compared against in the matching algorithm.
Files to be Compared
This field in the form is used to specify which files for each student’s version(s) are used in the matching algorithm. Instructors can specify which of the three directories –“submissions”, “results”, and “checkout” (see also Directory Structure) – to scan and grab submission files from.
In addition to specifying the directories, instructors can also
specify exact file names, or
regular expressions for the
file names, to be compared against in the algorithm. For example, if
we specify the file names “*.cpp, plaintext.txt” and the directories
“submissions” and “results”, then only files with the name
plaintext.txt or with the extension .cpp in those two directories
will be taken. The ! operator may also be prepended to a given pattern to
remove files which match the pattern from the selected files. For example,
given the files submission_a.cpp, submission_b.cpp, and submission_c.cpp: the
pattern *, !*a.cpp would select the files submission_b.cpp and submission_c.cpp
while the pattern !*a.cpp would not select any files because there are no matching
files to remove from the files list. To select all files except for ones of a
certain type, you must first select everything (*) and then remove files of
the desired type (!filename).
This field is particularly useful for when only certain files are of
interest to an instructor to run plagiarism detection on, like when
the files that are to be compared are not the files the students have
directly submitted, but the output of their autograded tests. Another
use case would be for gradeables to which students have submitted
multiple files of different kinds, that would each yield the best
results when run under different configuration parameters. For
instance, if all the students submitted a README.txt and a
main.cpp to a gradeable, then it might be helpful to make two
separate configurations, the first where the C++ files are run under
the C++ tokenizer (specified under the “Language” field, see next),
and the second where the README.txt are run under the plain text
tokenizer.
Language
The “Language” parameter affects the way regions of code from the student submissions are tokenized and compared against each other. For example, the “Plain Text” option would compare tokens by trying to find exact strings that match across submissions files, while the “C++” option would compare tokens in the context of the programming language syntax, so it would be blind to the specific text in variable names and comments.
Common Code Threshold
This field in the form represents the threshold for maximum the number of students who share a matching segment of code to be considered plagiarized. This means that if more students than the number specified as the threshold share matching code, the said shared code will be marked “common code” instead of as plagiarized, and will be specifically marked so in the run results UI. This threshold is useful for assignments where student solutions generally fall into the same category or approach, and naturally a large portion of the submissions match. Unique regions of match, where the number of students that share them is lower than the threshold, will still be identified and marked as plagiarized.
Hash Size
The hash size defines the amount of tokens in a section, or the window size, of code segments across student submissions that are to be hashed and compared. Different settings for the “Language” field will (see above) will probably require different settings for the hash size for optimal results, which is why for every supported language we have default recommended values for the hash size.
Other Gradeables
Instructors have the ability to include submissions from other prior or existing gradeables from their courses to be included in the matching algorithm. Only students in the current course will be brought up if plagiarism has been detected, but the result page will indicate if any of the plagiarized content matched the submissions of students from the other gradeables.
Users to be Ignored
This section of the configuration form allows the instructor to specify users whose submissions should not be included in the matching algorithm. This can be useful for example in courses where the instructors, TAs, or other graders submit files to gradeables in order to test the automated grading before the assignment is released to students, and where finding matches across the course staff’s test submissions is undesirable. Instructors also have the option to list specific student names whose submissions are to be ignored, if they wish so.
When you are done filling out the form, click the “Save Configuration”
button. The new configuration will be created, and will be
automatically placed in the daemon_job_queue queue. You will be
redirected to the main page, where you should see your newly created
configuration under the status “Running”.
Viewing the Results of a Run
To view the results of a gradeable configuration’s run, click the name of the gradeable in the main plagiarism page table.
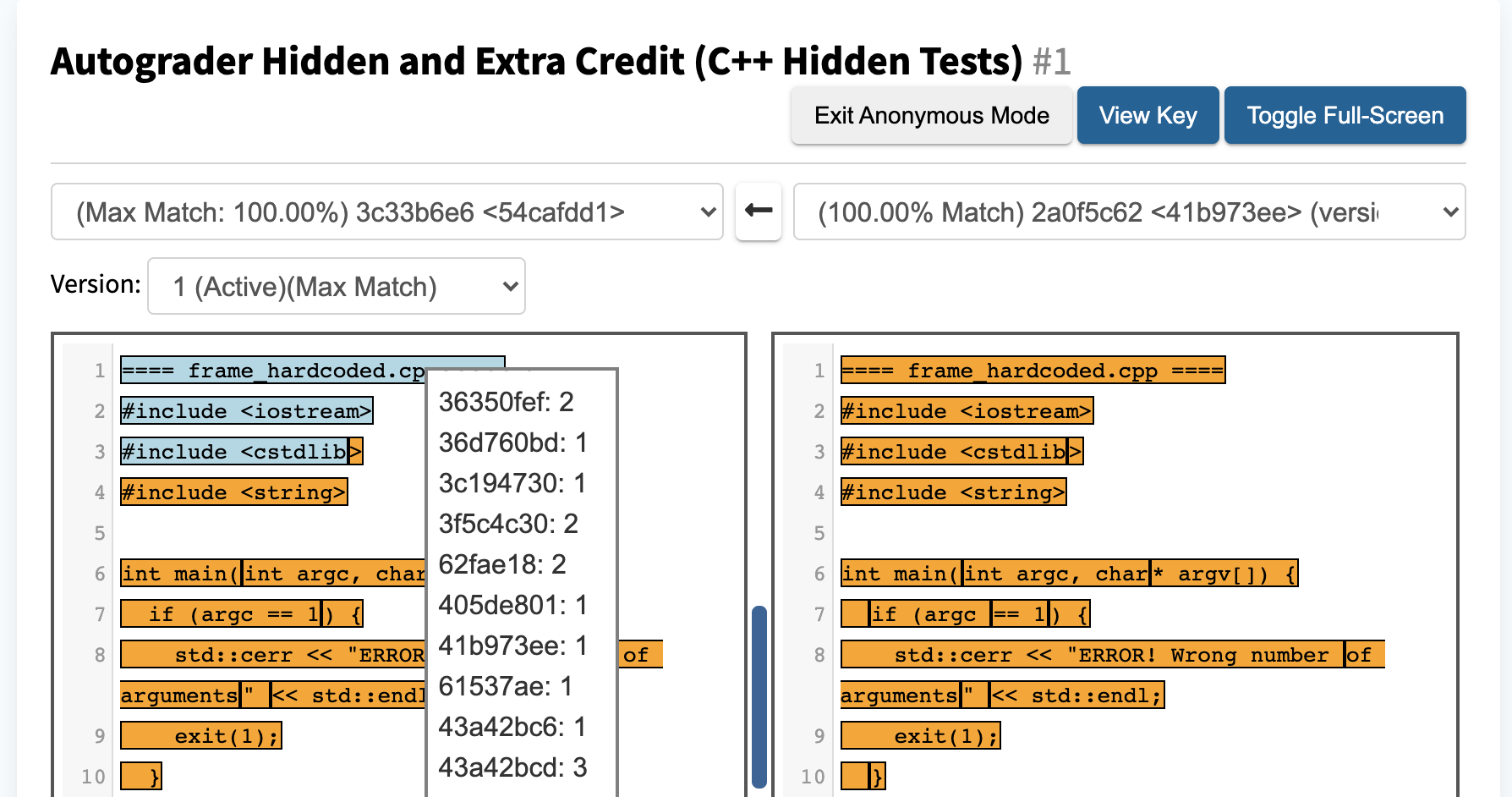
The top of the result page displays the gradeable name, as well as the configuration ID. The page layout is split into two panels, each that contains a dropdown menu of student submissions and a code block.
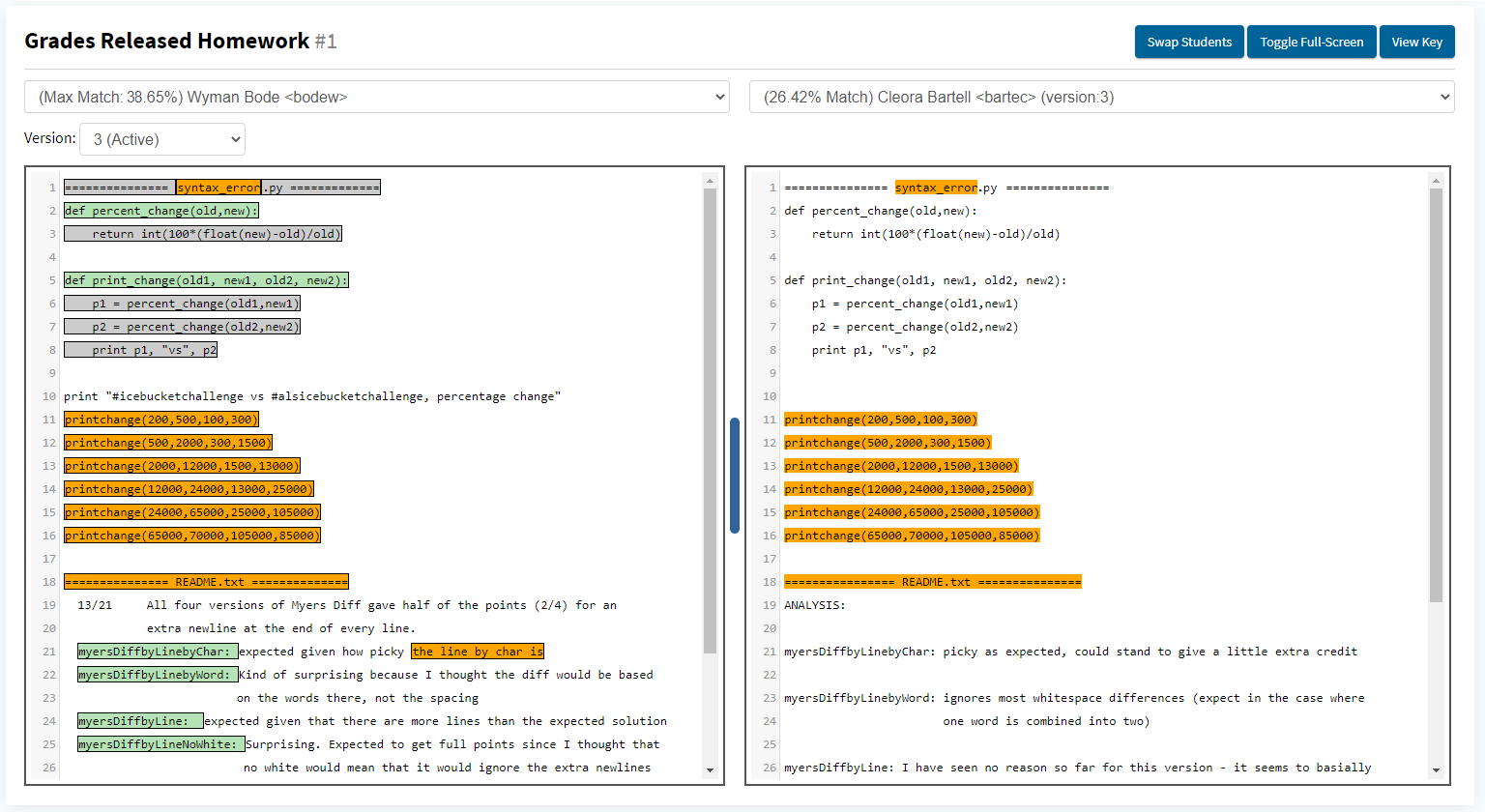
This design enables you to pick a user and a version on the left panel, and compare it to another student submission on the left.

The code block will display that concatenated files submitted by the student, and will highlight the matching regions. To see details about the meaning of the colors of the highlighted regions, click the “View Key” button on the top right corner of the page.
The panel on the left may highlight regions of code that are considered common code, match the instructor provided code, match other users than the user selected for the right panel, and matching code regions that the two selected users share. The right panel will only highlight the regions of code that matching between the two selected students, but if you wish to see the other types of matching regions for the user on the right, you can click the “Swap Students” button in the upper right corner of the page.
Clicking an orange-colored region of code in the left panel will turn it red, to indicate the selection of that region, and will scroll to and highlight red the corresponding matching region(s) over in the right panel as well. This can make the comparison easier when plagiarized sections of code don’t appear in the same location in the two files.
Clicking yellow-colored regions of code will prompt a popup of a clickable list of the other users who share the same matching region. To compare the same user who is selected on the left panel to one of the users in the popup, simply click the desired username, and the right panel will automatically update to show the submission that belongs to the new username.
Instructors are also able to toggle “Anonymous Mode” by clicking the button on the top right, which hides student names and ID’s and replaces them with random hashes to allow sharing screenshots and showing students accused of cheating the evidence against them with fewer confidentiality concerns.